
1. 2026년 2월 5일: AI의 '슈퍼 선데이'가 왔다
2026년 2월 5일, 전 세계 기술 커뮤니티는 숨을 죽였습니다. 인공지능 역사상 유례없는 정면충돌이 벌어졌기 때문입니다. OpenAI는 슈퍼볼(Super Bowl LX) 광고를 통해 '자기 자신을 개발하는 데 기여한' 최초의 상용 모델 GPT-5.3 Codex를 깜짝 공개했고, Anthropic은 이에 질세라 불과 몇 시간 뒤 Claude Opus 4.6을 전격 발표하며 맞불을 놓았습니다.
이날의 발표는 단순한 모델 업데이트를 넘어섰습니다. AI가 스스로 지능을 개선하는 단계에 진입했음을 알리는 신호탄이었으며, 100만 토큰의 거대한 컨텍스트 창이 상용 모델에서 표준이 된 역사적인 순간이었습니다. 개발자와 비즈니스 리더들은 이제 '어떤 모델이 더 나은가'를 넘어, '이 거대한 지능들을 어떻게 우리의 워크플로우에 통합할 것인가'라는 근본적인 질문에 직면해 있습니다.
오늘 이 가이드에서는 AI 업계의 두 거인이 내놓은 최신 병기들을 낱낱이 해부하고, 2026년의 새로운 AI 표준이 무엇인지, 그리고 당신의 비즈니스와 개발 환경에 어떤 모델이 최적일지 깊이 있게 분석해 보겠습니다.
2. Claude Opus 4.6: 인류의 마지막 시험을 향한 도약
Anthropic의 플래그십 모델, Claude Opus가 4.6 버전으로 다시 한번 진화했습니다. 지난 2025년 11월 4.5 버전을 선보인 지 불과 3개월 만입니다. 이번 업데이트의 핵심은 '지능의 깊이'와 '메모리의 확장'입니다.
출시 정보 및 가격 정책
- 출시일: 2026년 2월 5일
- 이전 버전: Opus 4.5 (2025-11-24)
- 가격: 100만 토큰당 입력 $5 / 출력 $25 (기존 Opus급 가격 유지)
- 컨텍스트 창: 1M Tokens (Beta) - Opus급 모델 최초 달성
- 최대 출력: 128K Tokens
벤치마크: 압도적인 추론 능력의 증명
Opus 4.6은 특히 '추상적 추론'과 '장문맥 이해'에서 경이로운 성장을 보여주었습니다.
| 벤치마크 | Opus 4.5 | Opus 4.6 | 향상도 |
|---|---|---|---|
| ARC-AGI-2 | 37.6% | 68.8% | +31.2%p 🔥 |
| BrowseComp | 67.8% | 84.0% | +16.2%p |
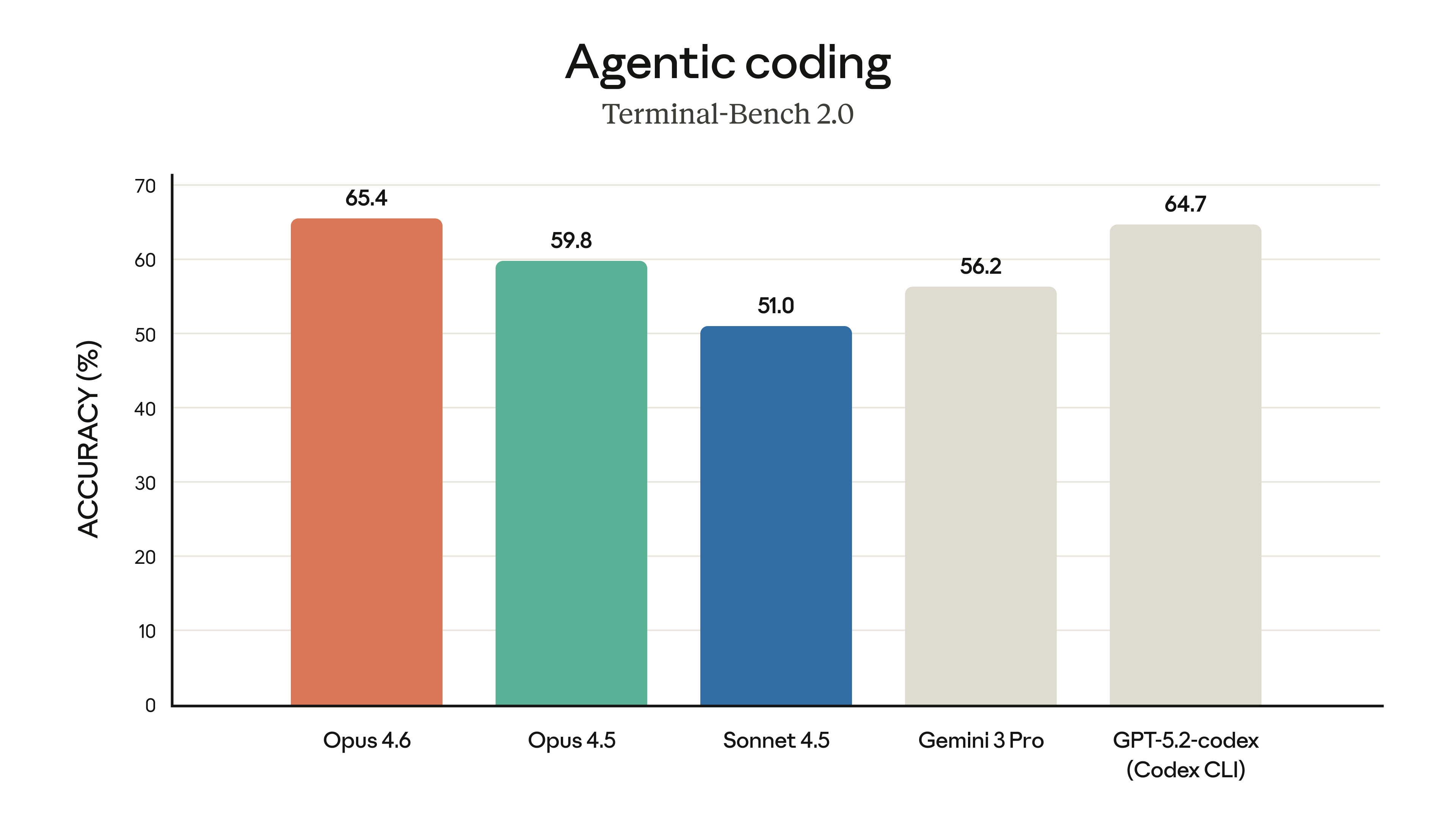
| Terminal-Bench 2.0 | 59.8% | 65.4% | +5.6%p |
| OSWorld | 66.3% | 72.7% | +6.4%p |
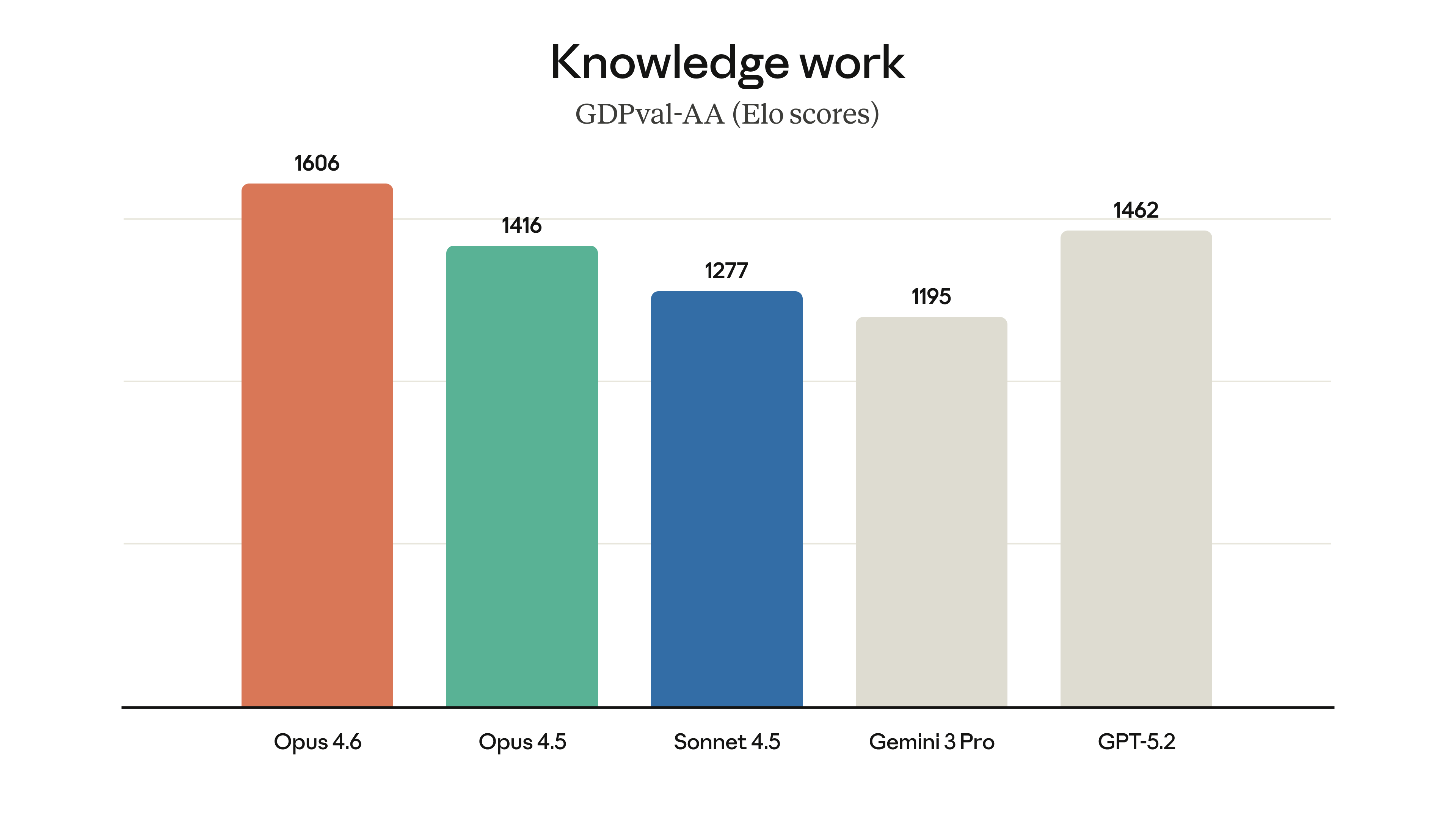
| GDPval-AA Elo | 1416 | 1606 | +190 |
| MRCR v2 (1M context) | 18.5% (Sonnet) | 76.0% | 대폭 향상 |
| τ2-bench Retail | 82.0% | 91.9% | +9.9%p |
| Humanity's Last Exam (w/ tools) | - | 53.1% | 신규 등재 |
| Finance Agent | 56.6% (5.2기준) | 60.7% | +4.1%p |
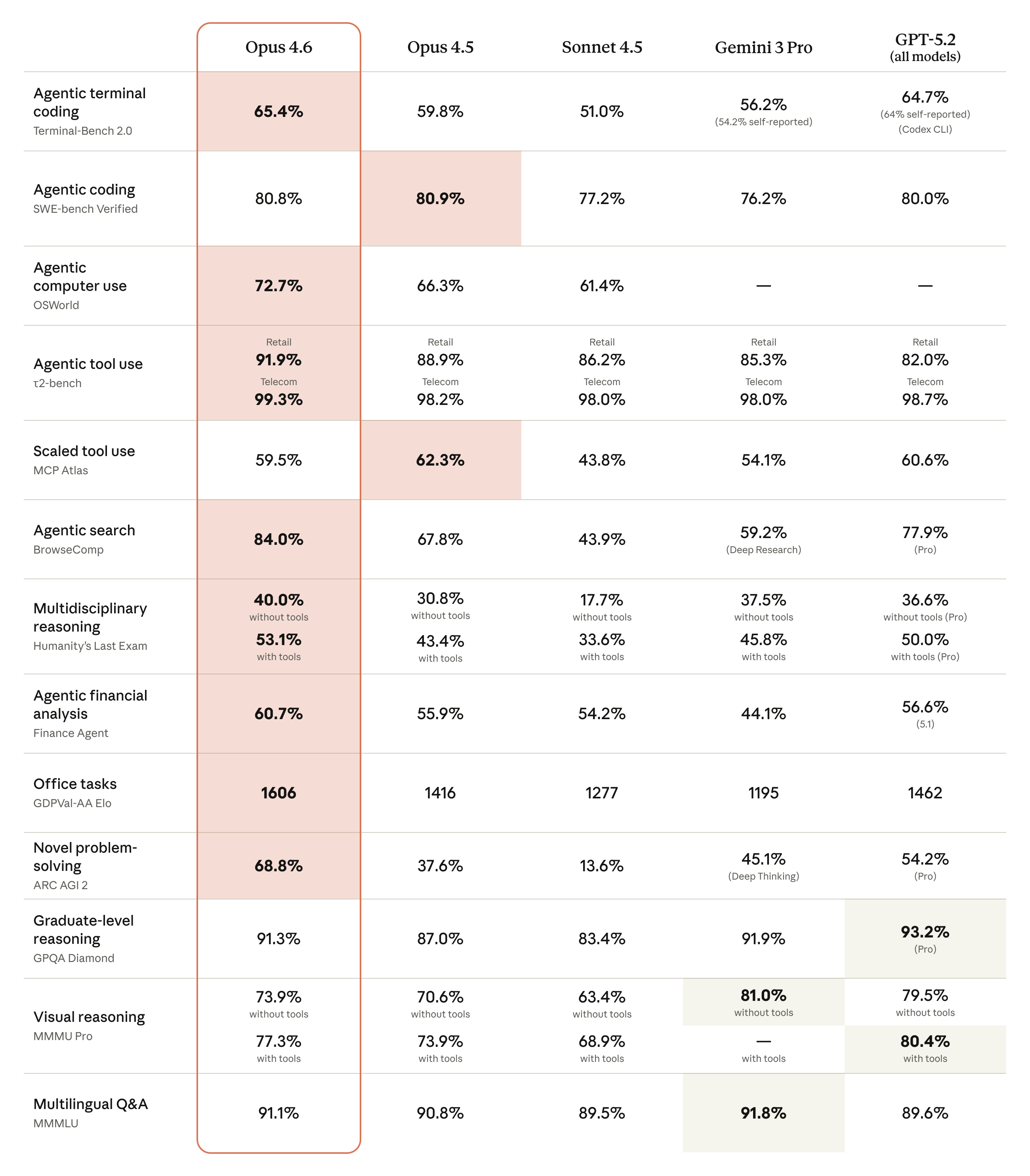
가장 눈에 띄는 것은 ARC-AGI-2 점수입니다. AI의 일반 지능을 측정하는 이 난공불락의 벤치마크에서 단숨에 31%p 이상을 끌어올리며 68.8%를 기록한 것은, Claude가 단순한 패턴 매칭을 넘어 인간에 가까운 '유연한 사고'를 하기 시작했음을 의미합니다.
Claude Opus 4.6의 5대 핵심 신기능
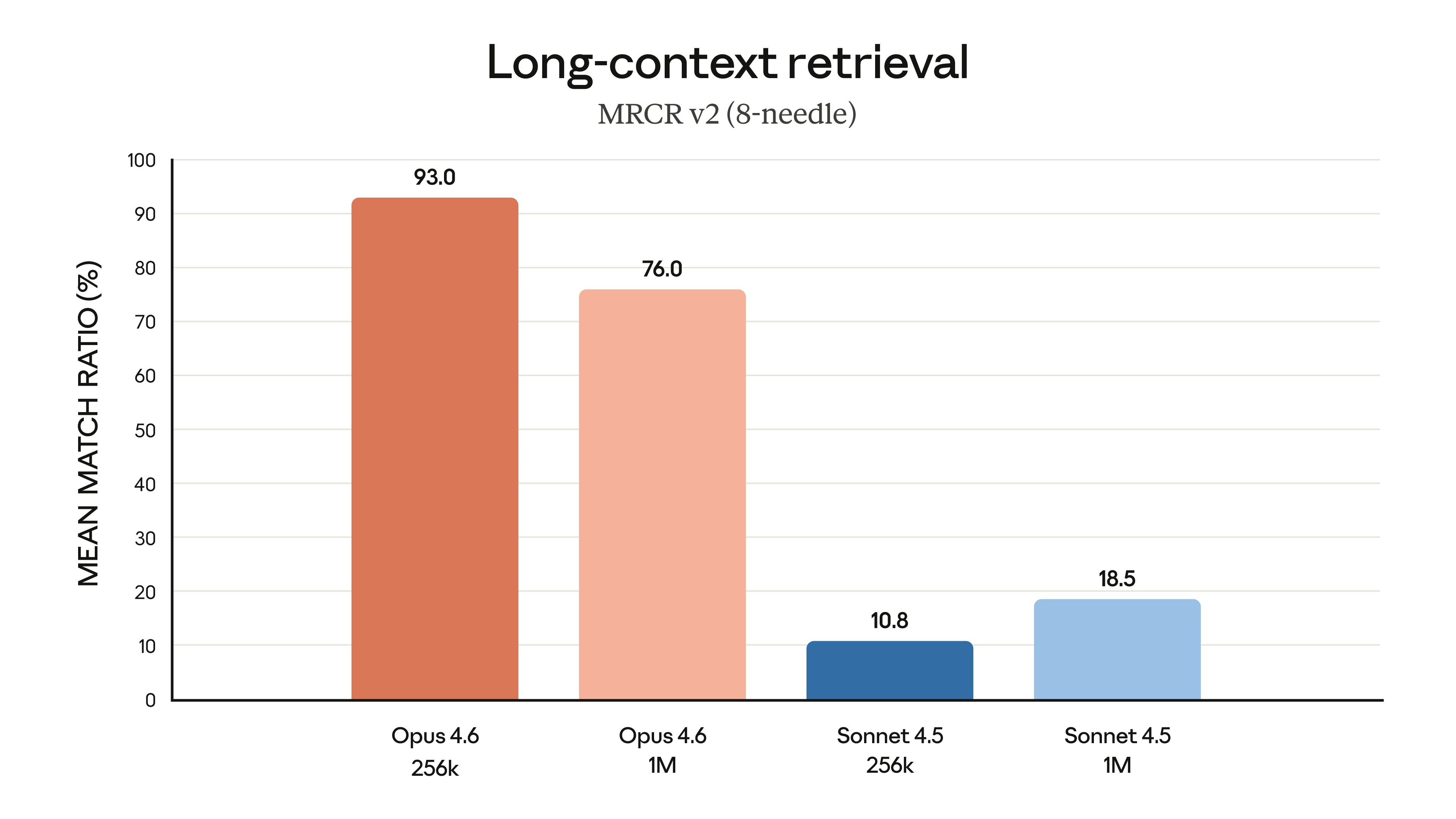
1. 1M Token Context Window (Beta)
Opus급 모델 중 최초로 100만 토큰의 컨텍스트 창을 지원합니다. 기존에는 Sonnet 모델에서만 제한적으로 가능했던 영역을 최고 성능 모델인 Opus로 확장한 것입니다. 특히 주목할 점은 MRCR(Multi-Round Context Retrieval) v2 벤치마크 결과입니다. Sonnet 4.5가 18.5%에 그쳤던 반면, Opus 4.6은 100만 토큰 전체에서 76%의 정확도를 유지했습니다. 이는 소위 '컨텍스트 부패(Context Rot)' 문제를 획기적으로 개선했음을 보여줍니다.
2. Agent Teams (Claude Code 연동)
이제 Claude는 혼자 일하지 않습니다. 'Agent Teams' 기능을 통해 여러 에이전트가 팀을 이루어 복잡한 프로젝트를 병렬로 수행합니다. 예를 들어, 한 에이전트가 레포지토리의 보안 취약점을 분석하는 동안, 다른 에이전트는 성능 최적화 포인트를 찾고, 세 번째 에이전트가 이 둘의 결과를 취합해 보고서를 작성합니다. 사용자는 Shift+Up/Down이나 tmux를 통해 각 서브에이전트의 상태를 실시간으로 모니터링하고 제어할 수 있습니다.
3. Adaptive Thinking
모델이 문제의 난이도에 따라 사고 과정을 스스로 조절합니다.
- Low: 단순한 팩트 체크나 코드 스니펫 생성 시 불필요한 추론을 줄여 속도와 비용 최적화
- Medium/High: 일반적인 개발 작업 및 분석
- Max: 고도의 수학적 증명이나 복잡한 시스템 아키텍처 설계 시 수천 단계의 사고 체인을 형성
4. Context Compaction (Beta)
긴 대화 세션에서 자동으로 중요 정보를 요약하고 불필요한 컨텍스트를 압축합니다. 이를 통해 토큰 효율성을 극대화하며, 수만 줄의 대화가 오가는 상황에서도 초기 논점이나 핵심 제약 조건을 잊지 않고 일관된 응답을 제공합니다.
5. Microsoft Office 통합 (Excel/PowerPoint)
Claude의 강력한 분석 능력이 Office 도구에 직접 이식되었습니다. 수백 개의 시트가 얽힌 엑셀 파일에서 이상 데이터를 탐지하거나, 수천 페이지의 문서를 단숨에 분석해 시각적으로 완벽한 파워포인트 슬라이드 덱을 구성하는 능력을 갖췄습니다.
글로벌 리더들의 실전 평가
- GitHub (Mario Rodriguez): "복잡한 다단계 코딩 작업에서 계획 수립과 도구 호출 능력이 타의 추종을 불허합니다. 인간 엔지니어가 며칠 걸릴 설계를 몇 분 만에 완벽하게 해냅니다."
- Rakuten (Yusuke Kaji): "단 하루 만에 13개의 백로그 이슈를 해결했습니다. 50명 규모의 조직에서 6개의 거대 레포지토리를 관리하는 데 Opus 4.6은 이제 필수적인 팀원입니다."
- Harvey (Niko Grupen): "법률 추론 벤치마크인 BigLaw Bench에서 90.2%를 달성했습니다. 판례 분석과 복잡한 계약서 검토에서 전문 변호사 수준의 디테일을 보여줍니다."
3. GPT-5.3 Codex: 스스로를 빚어낸 인공지능의 연금술
OpenAI가 공개한 GPT-5.3 Codex(코드명: Garlic)는 인공지능 발전사에서 매우 상징적인 모델입니다. 이는 인류가 아닌, 인공지능이 스스로의 코드를 디버깅하고 훈련 프로세스를 관리하여 성능을 개선한 최초의 '자가 진화형' 상용 모델이기 때문입니다.
출시 정보 및 접근 방식
- 출시일: 2026년 2월 5일
- 코드명: Garlic
- 가격 (5.2 기준): 입력 $1.75 / 출력 $14 (5.3 가격은 미공개이나 비슷할 것으로 예상)
- 접근 제한: 현재 API로 직접 제공되지 않음. 전용 Codex 앱, CLI, IDE 익스텐션을 통해서만 사용 가능.
- 대상: ChatGPT Plus, Pro, Team, Enterprise 구독자
벤치마크: 실행과 자동화의 끝판왕
GPT-5.3 Codex는 특히 터미널 환경에서의 작업 수행과 실무 코딩 벤치마크에서 압도적인 점수를 기록했습니다.
| 벤치마크 | GPT-5.2 | GPT-5.3 Codex | 향상도 |
|---|---|---|---|
| Terminal-Bench 2.0 | 62.2% | 77.3% | +15.1%p 🔥 |
| OSWorld-Verified | 37.9% | 64.7% | +26.8%p 🔥 |
| Cybersecurity CTF | 67.7% | 77.6% | +9.9%p |
| SWE-Lancer IC Diamond | 74.6% | 81.4% | +6.8%p |
| SWE-Bench Pro | 55.6% | 56.8% | +1.2%p |
| GDPval (wins/ties) | 70.9% | 70.9% | 0.0%p |
GPT-5.3 Codex의 5대 핵심 신기능
1. Self-Development (자가 개발 기여)
이 모델의 가장 경이로운 점은 훈련 과정에 있습니다. GPT-5.3은 자신의 훈련 데이터 세트를 정제하고, 손실 함수(Loss function)의 이상 징후를 스스로 탐지하여 디버깅했으며, 최종 배포를 위한 인프라 관리까지 직접 수행했습니다. "AI가 AI를 만드는 시대"가 실질적으로 시작되었음을 증명하는 대목입니다.

2. Mid-turn Steering
기존 모델들은 결과물이 나올 때까지 기다려야 했지만, Codex는 작업 진행 중에 실시간으로 방향을 틀 수 있습니다. 모델이 복잡한 코드를 작성하는 도중 "아, 그 부분은 다른 라이브러리를 써줘"라고 개입하면, 문맥을 잃지 않고 즉시 코드를 수정하며 진행합니다. 이는 개발자와 AI 사이의 실시간 협업 경험을 비약적으로 향상시킵니다.
3. 25% 빠른 반응 속도
GPT-5.2 대비 추론 속도가 25% 향상되었습니다. 단순히 텍스트가 빨리 나오는 것을 넘어, 에이전트가 도구를 호출하고 결과를 분석하는 전체 루프가 빨라졌음을 의미합니다.
4. 사이버보안 'High Capability' 등급 획득
OpenAI의 대비 프레임워크(Preparedness Framework)에서 최초로 보안 역량 'High' 등급을 받았습니다. 이는 모델이 복잡한 시스템의 제로데이 취약점을 탐지하고 방어 전략을 수립하는 데 있어 전문가 수준에 도달했음을 뜻합니다. OpenAI는 이를 위해 1,000만 달러 규모의 사이버 방어 지원 프로그램을 함께 런칭했습니다.
5. 자율적 웹/앱 반복 개선
사용자가 모호한(underspecified) 프롬프트를 주더라도, Codex는 스스로 여러 버전의 데모를 만들어 제안하고 반복적으로 다듬습니다. 데모로 공개된 '레이싱 게임(racing_v2.html)'과 '다이빙 게임(diving_game.html)'은 단 한 줄의 기획 문구로 시작해 상용 수준의 게임으로 완성되는 과정을 보여주며 큰 충격을 주었습니다.

4. 격돌의 장: Terminal-Bench 2.0 리더보드 (2026-02-06 기준)
실제 터미널 환경에서 명령어를 실행하고 시스템을 제어하는 능력을 측정하는 'Terminal-Bench 2.0'은 현재 에이전트 모델의 성능을 가늠하는 가장 중요한 척도입니다.
| 순위 | 에이전트 이름 | 탑재 모델 | 정확도 (Accuracy) |
|---|---|---|---|
| 1 | Simple Codex | GPT-5.3-Codex | 75.1% ± 2.4 |
| 2 | Droid | Claude Opus 4.6 | 69.9% ± 2.5 |
| 3 | Droid | GPT-5.2 | 64.9% ± 2.8 |
| 4 | Ante | Gemini 3 Pro | 64.7% ± 2.7 |
| 5 | Terminus 2 | GPT-5.3-Codex | 64.7% ± 2.7 |
GPT-5.3 Codex는 터미널 작업에서 75.1%라는 압도적인 점수로 1위를 차지했습니다. 반면, Claude Opus 4.6은 69.9%로 바짝 뒤를 쫓고 있습니다. 수치상으로는 GPT의 우위지만, Claude는 ARC-AGI-2와 같은 '추론' 벤치마크에서 우위를 점하고 있어, "실행의 GPT, 사고의 Claude"라는 구도가 더욱 명확해지고 있습니다.
5. 2026년 2월 5일의 동시 출시: 무엇을 의미하는가?
왜 두 회사는 같은 날 신모델을 내놓았을까요? 이는 단순한 우연이 아닙니다.
1. 슈퍼볼 광고 전쟁 (Super Bowl LX)
OpenAI는 수천만 명이 지켜보는 슈퍼볼 기간에 맞춰 GPT-5.3을 공개하며 대중적 인지도를 폭발시켰습니다. 반면 Anthropic은 슈퍼볼 당일, 기술적 우위를 강조하는 데이터를 쏟아내며 '실무자와 엔지니어를 위한 진정한 강자'라는 프레임을 구축했습니다.
2. AI 우주 경쟁 (Space Race 2.0)
1960년대의 우주 경쟁처럼, 이제 AI 패권은 국가와 기업의 명운이 걸린 문제가 되었습니다. 에이전틱 AI(Agentic AI)가 실무 환경에 본격 투입되는 2026년에 주도권을 뺏기지 않으려는 두 거인의 처절한 싸움이 시작된 것입니다.
6. 모델 활용 6단계 워크플로우
새로운 모델들을 팀에 도입하기 위한 최적의 프로세스입니다.
- 현재 워크플로우 평가: 팀에서 가장 시간을 많이 잡아먹는 작업(코드 리뷰, 데이터 분석, 인프라 관리 등)을 식별합니다.
- 모델 강점 매칭: 고도의 논리가 필요한 추론 작업은 Opus 4.6으로, 터미널 조작이나 반복적 코딩 작업은 Codex로 할당합니다.
- 하이브리드 전략 수립: 두 모델의 API를 연동하여 상호 보완적인 파이프라인을 구축합니다. (예: Opus가 계획을 짜고 Codex가 실행)
- 파일럿 테스트 실행: 소규모 프로젝트에서 1M 컨텍스트와 Mid-turn Steering 기능을 직접 테스트하며 생산성 지표를 측정합니다.
- 성능 모니터링 및 최적화: Adaptive Thinking 설정을 조정하며 비용 대비 성능 효율을 최적화합니다.
- 전사 롤아웃 및 교육: 성공 사례를 공유하고 팀원들에게 모델별 특성을 교육하여 활용도를 높입니다.
7. 주요 유즈케이스 (Real-world Scenarios)
시나리오 1: 대규모 코드베이스 마이그레이션 (Opus 4.6)
수백만 줄의 레거시 코드를 최신 프레임워크로 옮길 때, Opus 4.6의 1M 컨텍스트는 전체 시스템 구조를 한눈에 파악합니다. 수천 개의 파일 간 의존성을 분석해 충돌 없는 마이그레이션 계획을 수립하고 실행합니다.
시나리오 2: 실시간 자율 개발 자동화 (GPT-5.3 Codex)
새로운 마이크로서비스를 구축할 때, Codex의 Mid-turn Steering을 활용합니다. 개발자가 실시간으로 개입하며 인프라 구축, API 설계, 테스트 코드 작성을 동시다발적으로 진행하여 개발 속도를 3배 이상 높입니다.
시나리오 3: 복잡한 법률/금융 문서 심층 분석 (Opus 4.6)
수천 페이지의 계약서와 시장 보고서를 한 번에 입력하여 숨겨진 리스크를 찾아냅니다. Opus 4.6은 1M 토큰 전체를 높은 정확도로 검색하므로, 특정 조항의 모순점이나 데이터의 미세한 변화를 놓치지 않습니다.
8. 팁 및 베스트 프랙티스
💡 팁 1: 장문맥 작업은 Opus 4.6의 1M 컨텍스트를 최우선으로 고려하세요.
단순 검색(Retrieval)을 넘어 전체 맥락을 이해해야 하는 작업에서 Opus 4.6은 타 모델이 따라올 수 없는 정확도를 보여줍니다.
💡 팁 2: 터미널 기반 자동화는 GPT-5.3 Codex의 강점을 활용하세요.
시스템 명령어를 실행하고 서버 환경을 설정하는 에이전트 구축 시 Codex의 높은 정확도는 오류를 획기적으로 줄여줍니다.
💡 팁 3: 추상적 사고가 필요한 문제는 Opus 4.6에게 맡기세요.
ARC-AGI-2에서 증명된 것처럼, 전례 없는 새로운 논리 문제를 해결할 때 Claude의 창의적인 사고 능력이 빛을 발합니다.
💡 팁 4: 중간 개입이 잦은 작업은 Mid-turn Steering을 적극 활용하세요.
결과가 마음에 들지 않을 때 끝까지 기다리지 말고 중간에 방향을 잡아주어 시간을 절약하세요.
💡 팁 5: 비용 효율성을 위해 Sonnet 4.5와 Opus 4.6을 조합하세요.
일반적인 작업은 상대적으로 저렴한 Sonnet 4.5(또는 GPT-5.2)에게 맡기고, 최종 검증이나 핵심 설계만 Opus 4.6이나 Codex로 처리하는 하이브리드 방식이 경제적입니다.
⚠️ 주의: GPT-5.3 Codex는 현재 API로 제공되지 않으므로, 자동화 시스템 구축 시 이 점을 반드시 고려해야 합니다.
9. 결론: 이제 선택의 시간입니다
2026년 2월, 우리는 인공지능이 도구가 아닌 '지능형 동반자'로 거듭나는 역사적 현장에 서 있습니다.
Claude Opus 4.6은 인간의 사고방식을 가장 가깝게 모사하며 거대한 지식을 한 번에 처리하는 '현자'와 같습니다. 반면 GPT-5.3 Codex는 스스로를 개선하며 실제 세상을 조작하는 능력이 극대화된 '기술자'에 가깝습니다.
당신의 목표가 복잡한 세상을 깊이 있게 이해하고 분석하는 것이라면 Anthropic의 길을, 아이디어를 빛의 속도로 현실화하고 실행하는 것이라면 OpenAI의 길을 선택하십시오. 아니, 어쩌면 가장 현명한 답은 이 두 거인의 지능을 적재적소에 배치하여 당신만의 거대한 지능 시스템을 구축하는 것일지도 모릅니다.
10. TL;DR
- 발표 날짜: 2026년 2월 5일, OpenAI와 Anthropic의 동시 신모델 공개.
- Claude Opus 4.6: 100만 토큰 컨텍스트, ARC-AGI-2 31.2%p 폭등, Agent Teams를 통한 협업 강화.
- GPT-5.3 Codex: AI가 직접 개발에 참여한 최초의 모델, 터미널 제어 능력 1위(75.1%), Mid-turn Steering 지원.
- 주요 차이점: 추론과 분석은 Opus 4.6이 우세, 실행과 실시간 수정은 GPT-5.3 Codex가 우세.
- 접근성: Opus 4.6은 API 제공 중, GPT-5.3 Codex는 전용 앱/IDE에서만 사용 가능(API 곧 제공 예정).
- 핵심 전략: "사고는 Claude에게, 실행은 GPT에게" 맡기는 하이브리드 전략이 2026년의 정석.
11. 참고 링크
Claude Opus 4.6
GPT-5.3 Codex
벤치마크 분석
'AI' 카테고리의 다른 글
| OpenClaw Tools & Discord 연결 가이드 (0) | 2026.02.07 |
|---|---|
| OpenClaw 상세 설치 가이드 - 초보자용 (0) | 2026.02.06 |
| [4편] CliProxyAPI 완벽 가이드 - CLI AI 모델을 표준 API로 통합하기 (0) | 2026.02.06 |
| Reverse-SynthID 완벽 분석 - 구글의 워터마크를 뚫어보자 (0) | 2026.02.06 |
| [3편] OpenCode + Custom Agents 가이드 - 커스텀 에이전트와 멀티 에이전트 오케스트레이션 (1) | 2026.02.05 |



